

- 売上予測などを線形回帰モデルで行いたい人。
- 外れ値が多いデータの取り扱いを知りたい人。
- 線形モデルを業務運用に用いたい人。
最近は機械学習モデルが人気のようですが、回帰分析やロジスティクス回帰などの統計モデルも実用性や解釈の容易さでそれらに劣らず人気があります。一方でこれら回帰系の統計モデルは決定木などと比較して外れ値の影響を受けやすい性質があります。
本稿では外れ値処理について扱うのですが処理方法ではなく処理の対象となるデータについて考察してみます。
使用したコードはhttps://github.com/mitsu666/blogにあります。
外れ値が与える影響
外れ値は分布の中心から大きく外れた値です。厳密な定義があるわけではないですが、例えば数年に一度あるかないかの真夏日だとか、年間に来店回数が300日の顧客だとかが実務では外れ値として扱うことが多いです。 この外れ値は線形回帰やロジスティクス回帰などの線形モデルの推定に悪影響を与えることがあります。以下の例でみてみましょう。左の図(外れ値がない)から意図的に外れ値を作成したデータが右図です。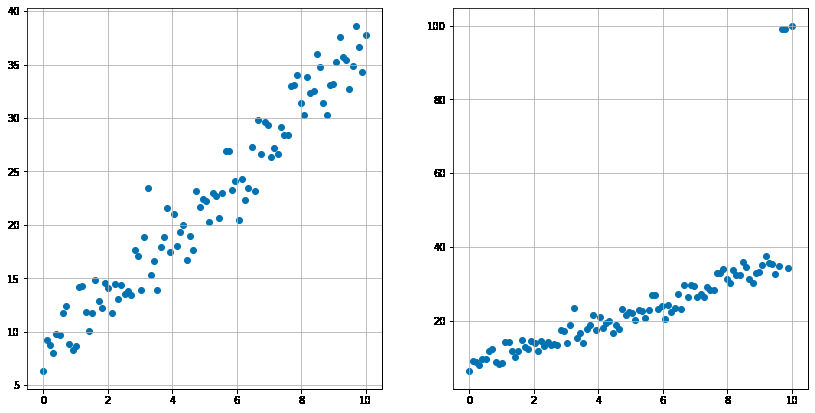
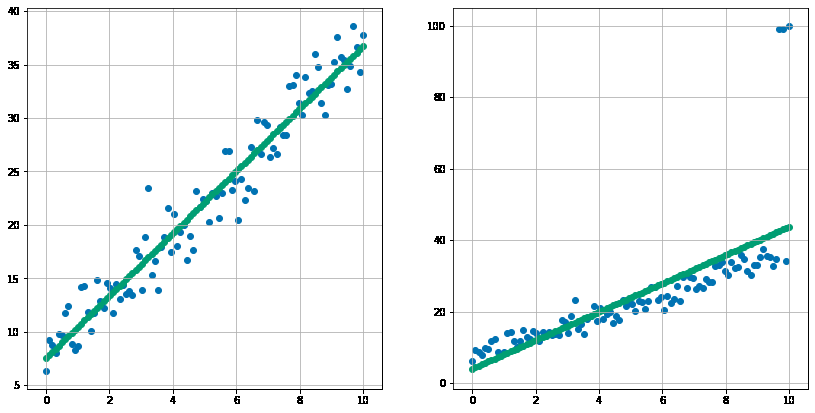
処理の方法ではなく外れ値処理を行う対象を整理する
元来古典的な統計学の世界では回帰モデルやそれに準ずる手法は、データの説明や解釈の用途に重きをおいてきました。一方でスコアリングの実装の容易さから予測に用いられることも当然あります。この際予測用のデータに訓練データと同じ処理をすべきか、またはすべきなのに実装フェーズでは忘れらているのではないのか?という問いが筆者の問題意識としてありました。よく見かけた例が- 学習データで外れ値を除外してモデルを作成した。実際にスコアリングする新たなデータでも同じように除外してしまっている。そのため分布の端っこのデータに予測値が付与されない。
- 学習データで99%タイルで外れ値を丸めたが、新しいスコアリングするデータで処理する際その99%タイル(すなわち学習データを丸めた時の閾値と異なる値で丸めてしまっている)で外れ値を丸めてしまった。または外れ値処理を新しいデータには行っていない。
- 学習データのターゲット変数に外れ値処理を行い、検証データでも外れ値処理を行い精度を測定してしまっている。(実際に新しくスコアリングするデータにターゲット変数はないため検証になっていない)
#丸目関数作成
def roundout(col,pct,train_col):
pct_low = np.percentile(train_col,pct)
pct_high = np.percentile(train_col,100-pct)
col[col<pct_low] = pct_low
col[col>pct_high] = pct_high
return (col)
検証結果
結果は以下の通りでした。尚精度はRMSEです。何もしない場合と比較し、除去する場合の精度は著しく良いです。一方でこれは当てにくいところを落としているからともいえます。2-123で比較すると、説明変数・ターゲット変数双方に処理を行い、検証データでも説明変数に処理を施したものが一番良い結果となっています。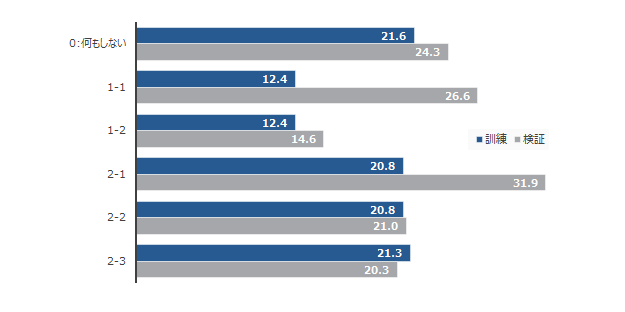
Author Profile

-
2007年より金融機関向けデータ分析業務に従事。与信及びカードローンのマーケテイングに関する数理モデルを作成。その後大手ネット広告会社にてアドテクノロジーに関するデータ解析を行う。またクライアントに対してデータ分析支援及び提言/コンサルティング業務を行う。統計モデルの作成及び特にビジネスアウトプットを重視した分析が得意領域である。統計検定1級。
技術・研究のこと:qiita
その他の個人的興味:note
お問い合わせは株式会社Crosstabまでお願いいたします
Latest entries
 ANALYTICS2024.04.12どうしてマーケティング系ツールは使われなくなるのか
ANALYTICS2024.04.12どうしてマーケティング系ツールは使われなくなるのか COLUMN2024.03.18生産管理のための機械スケジューリングの最適化 (最適化シリーズ Vol.1)
COLUMN2024.03.18生産管理のための機械スケジューリングの最適化 (最適化シリーズ Vol.1) AI2024.02.15GPTsとAssistants APIでノーコードでGPTをカスタマイズしSlackと連携する
AI2024.02.15GPTsとAssistants APIでノーコードでGPTをカスタマイズしSlackと連携する ANALYTICS2023.12.19正しく値上げするための価格弾力性分析
ANALYTICS2023.12.19正しく値上げするための価格弾力性分析